In [4]:
sns.scatterplot(data=df,x="Income",y="CrimeRate")
Out[4]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f514df850a0>

import pandas as pd
import seaborn as sns
df = pd.DataFrame({
"Income": [0.49, 0.18, 0.31, 0.40, 0.24],
"CrimeRate": [0.09, 0.45, 0.23, 0.19, 0.48]
})
soup.element and soup.find(element) both give you the first instance of element in the soupsoup.find_all returns a list (even if it's an empty one)Understand the near-universal assumption of machine learning models: unseen data is drawn from the same distribution as the training dataset, and the implications of this assumption.
Understand the meaning of and distinction between unsupervised learning and supervised learning.
Understand the meaning of and distinction between discriminative and generative learning.
Know how to define bias, variance and irreducible error
Be able to identify the most common causes of the above types of error, and explain how they relate to generalization, risk, overfitting, underfitting.
Bonus:
Overview: three steps:
sns.scatterplot(data=df,x="Income",y="CrimeRate")
<matplotlib.axes._subplots.AxesSubplot at 0x7f514df850a0>
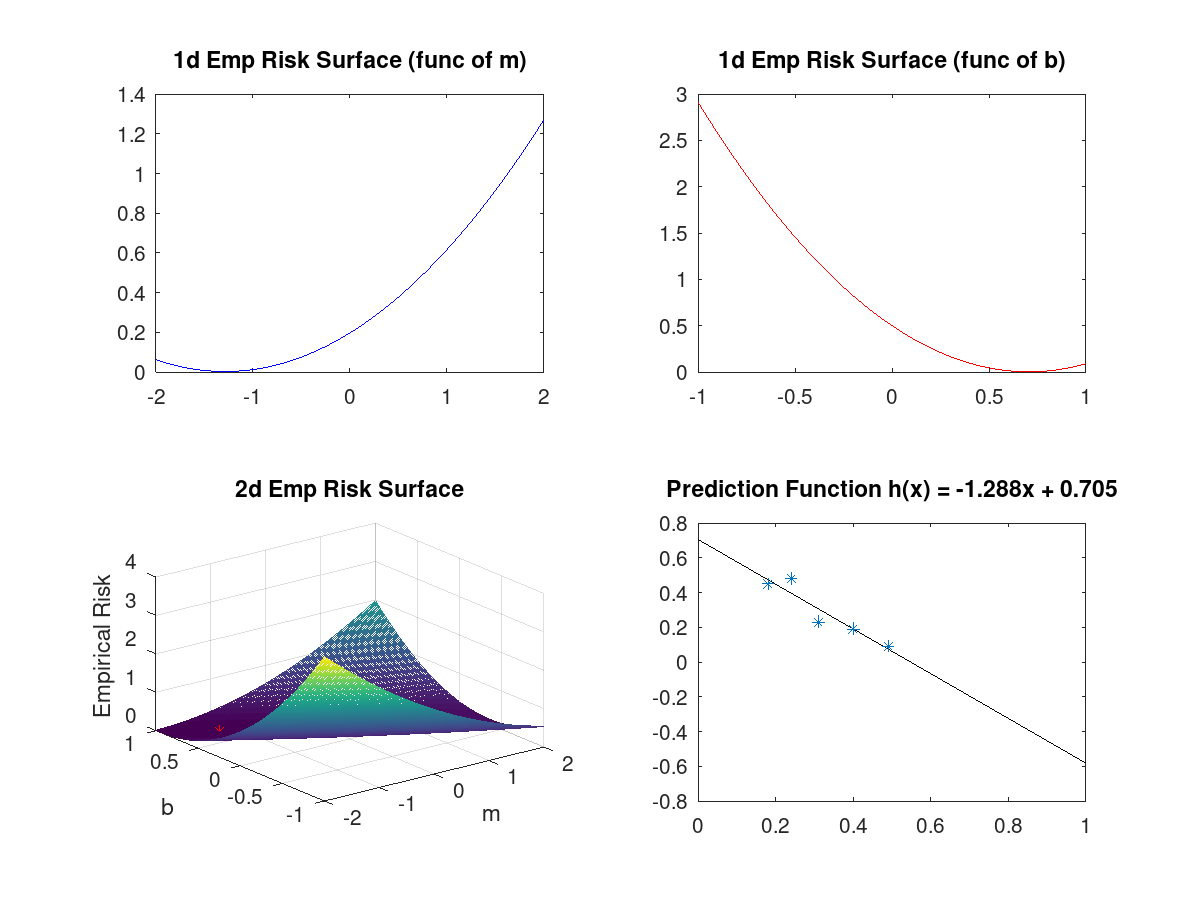
Training means solving the following optimization problem: $$ h^* = \arg\min_{h} \hat{R}(h; {\cal X})$$ Let's break this down:
Solving this problem requires math we can't count on in this class, so let's jump to the solution: $$ h^*(x) \approx -1.29x + 0.71$$
A way to describe a prediction task, depending on the value(s) being predicted:
If outputs are real-valued (continuous): this is a regression task.
If outputs are categorical (discrete): this is a classification task.
Supervised Learning, by example:
Key property: a dataset $X$ with corresponding "ground truth" labels $\mathbf{y}$ is available, and we want be able to to predict a $y$ given a new $\mathbf{x}$.
Unsupervised Learning, by example:
Key property: you aren't given "the right answer" - you're looking to discover structure in the data.
Given a set of data $X$ and (possibly) labels $y$ (i.e., quantities to predict), model either $P(y | x)$ or $P(x, y)$.
Recall: If you know $P(x, y)$, you can compute $P(y | x)$:
$$P(y | x) = \frac{P(x, y)}{P(x)}$$and $$P(x) = \sum_i P(x,y_i)$$
Let's apply this probabilistic interpretation to our crime rate prediction task:
sns.scatterplot(data=df,x="Income",y="CrimeRate")
<matplotlib.axes._subplots.AxesSubplot at 0x7f514db306d0>
For the moment, let's focus on supervised classification for the moment. In this case, $\mathbf{x}$ is a vector and $y$ is a discrete label indicating one of a set of categories or classes.
Discriminative models try to estimate $P(y | \mathbf{x})$. If you know this, then pick the most likely label, i.e., the $y$ that maximizes $P(y | \mathbf{x})$, and that's your predicted label for $\mathbf{x}$.
Generative models try to estimate $P(\mathbf{x})$ (if there are no labels $y$), or $P(x, y)$ if labels exist.
Note: it's easy to conclude that classification and discriminative are the same thing; they're not! Classifiers are often discriminative, but not always. How does that work?
Consider two schemes for classifying penguin species given their bill length and depth.
Exercise: Which of these is generative and which is discriminative?


Automatically detecting outlier images - like lab 4, except fully automatic.
Using linear regression (i.e., a best-fit line) to predict home value based on square feet given a set of actual home data from Zillow.
Finding "communities" of people who frequently interact with each other on a social network given a dataset of information about their social interactions on the network.
Generally: unseen data is drawn from the same distrubtion as your dataset.
Consequence: We don't assume correlation is causation, but we do assume that observed correlations will hold in unseen data.
Specific models: many more!
For example, linear regression assumes:

Generalization is the ability of a model to perform well on unseen data (i.e., data that was not in the training set).
sns.scatterplot(data=df,x="Income",y="CrimeRate")
We limited our model class to linear functions. What other choices might we make?
What effect does this choice have on the optimal value of $\hat{R}(h; \mathcal{X})$?
What effect does this choice have on the model's ability to generalize to unseen data?
What we truly care about is a quantity known as (true) risk: $R(h; {\cal X})$.
There are three contributors to risk:
To understand bias and variance, we need to consider hypothetical:
{kind=link}
{kind=link}