Given a set of data $X$ and (possibly) labels $y$ (i.e., quantities to predict), model either $P(y | x)$ or $P(x, y)$.
Recall: If you know $P(x, y)$, you can compute $P(y | x)$:
$$P(y | x) = \frac{P(x, y)}{P(x)}$$and $$P(x) = \sum_i P(x,y_i)$$
import pandas as pd
import seaborn as sns
df = pd.DataFrame({
"Income": [0.49, 0.18, 0.31, 0.40, 0.24],
"CrimeRate": [0.09, 0.45, 0.23, 0.19, 0.48]
})
sns.scatterplot(data=df,x="Income",y="CrimeRate")
<matplotlib.axes._subplots.AxesSubplot at 0x7fa5664044f0>

Outputs are real-valued (continuous): this is a regression task.
Predicting categorical outputs is called a classification task.
Overview: three steps:
Training means solving the following optimization problem: $$ h^* = \arg\min_{h} \hat{R}(h; {\cal X})$$ Let's break this down:
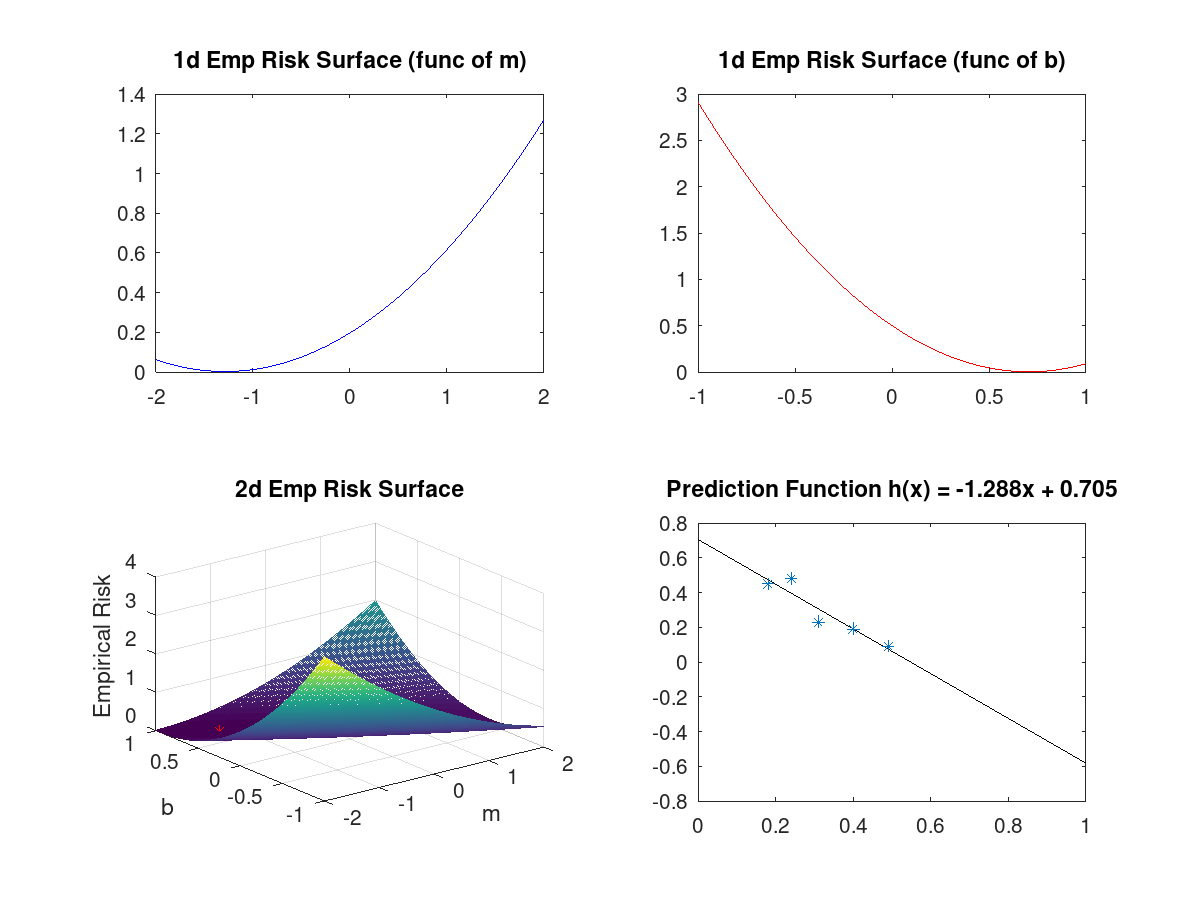
Solving this problem requires math we can't count on in this class, so let's jump to the solution: $$ h^*(x) \approx -1.29x + 0.71$$
sns.scatterplot(data=df,x="Income",y="CrimeRate")
<matplotlib.axes._subplots.AxesSubplot at 0x7fa5662f2e80>
We limited our model class to linear functions. What other choices might we make?
What effect does this choice have on the optimal value of $\hat{R}(h; \mathcal{X})$?
What would you choose if you needed to deploy a model to make predictions on unseen datapoints?
Supervised Learning, by example:
Key property: a dataset $X$ with corresponding "ground truth" labels $\mathbf{y}$ is available, and we want be able to to predict a $y$ given a new $\mathbf{x}$.
Unsupervised Learning, by example:
Key property: you aren't given "the right answer" - you're looking to discover structure in the data.
For the moment, let's focus on supervised classification for the moment. In this case, $\mathbf{x}$ is a vector and $y$ is a discrete label indicating one of a set of categories or classes.
Discriminative models try to estimate $P(y | \mathbf{x})$. If you know this, then pick the most likely label, i.e., the $y$ that maximizes $P(y | \mathbf{x})$, and that's your predicted label for $\mathbf{x}$.
Generative models try to estimate $P(\mathbf{x})$ (if there are no labels $y$), or $P(x, y)$ if labels exist.
Note: it's easy to conclude that classification and discriminative are the same thing; they're not! Classifiers are often discriminative, but not always. How does that work?
Consider two schemes for classifying penguin species given their bill length and depth.
Exercise: Which of these is generative and which is discriminative?


Automatically detecting outlier images - like lab 4, except fully automatic.
Using linear regression (i.e., a best-fit line) to predict home value based on square feet.
Finding "communities" of people who frequently interact with each other on a social network.
Generally: unseen data is drawn from the same distrubtion as your dataset.
Consequence: We don't assume correlation is causation, but we do assume that observed correlations will hold in unseen data.
Specific models: many more! Example:
Linear regression assumes:



{kind=link}
{kind=link}