Binary Classification¶
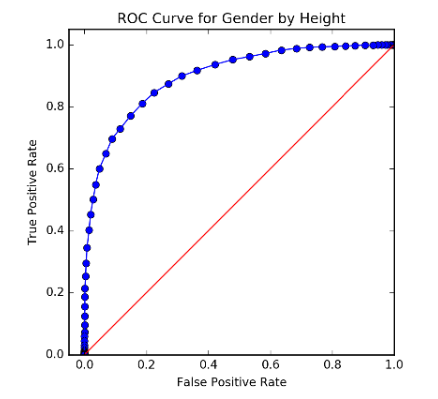
This is trickier than regression, and the reason is that most intuitive metrics can be gamed using a well-chosen baseline.
Simplest metric - accuracy: on what % of the examples were you correct?
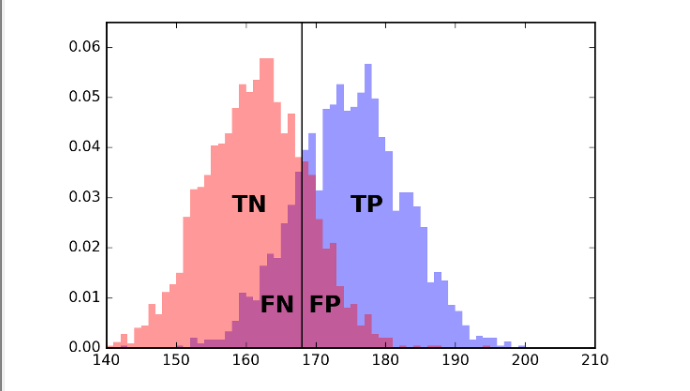
There are different kinds of right and wrong:
- TP - True positives (correctly labeled positive)
- TN - True negatives (correctly labeled negative)
- FP - False positives (incorrectly labeled positive; was actually negative)
- FN - False negatives (incorrectly labeled negative; was actually positive)
Exercise: let TP be the number of true positives, and so on for the other three. Define accuracy in terms of these quantities.