Terminology and Problem Setup¶
Feature Vectors¶
Machine learning only works on vectors. If you have something else (text, images, penguins, bananas), you'll need to convert them to vectors first.
These vectors are called feature vectors; each dimension is an individual feature; in this course we've been calling these columns.
The process of going from things to feature vectors is called feature extraction.
Observation: vectors can only contain numbers, so categorical columns usually need to be either dropped or converted to numbers somehow.
Dataset and Labels¶
We'll assume that we have a collection of a bunch of feature vectors (we've been calling it a table), one for each datapoint. This is our dataset.
A collection of vectors can be packaged into a matrix. The traditional way to do this is to call it $X$ and arrange the dimensions it like we're used to with our tables, so $X_{n \times d}$ contains $n$ rows, each of which is a $d$-dimensional feature vector for a datapoint.
Sometimes, we also have values for some quantity we'd like to predict, one value per datapoint in our dataset. These are called labels, and traditionally written $\mathbf{y}_{n \times 1}$, so $y_i$ is the label for the $i$th row of $X$.
Note: The word "label" may connote that it is categorical, but this is not necessarily true.
Problem Statement¶
Given $X$:
- discover some hidden structure in or properties of $X$
Given $X$ and $\mathbf{y}$:
- determine the most likely $y^*$ for some feature vector $\mathbf{x}^*$ that is not part of $X$.
Examples:
- $X$ is a table of $n$ houses with $d$ numbers about them (square feet, # bedrooms, ...); $\mathbf{y}$ is a vector of their market values.
- Same setup, but instead of predicting $y$ for a new $\mathbf{x}$, you want to know which of the $d$ variables are most predictive, or you want to discover the structure of the neighborhoods in a city.
We generally go about this by training (i.e., fitting) a model to our dataset $X$.




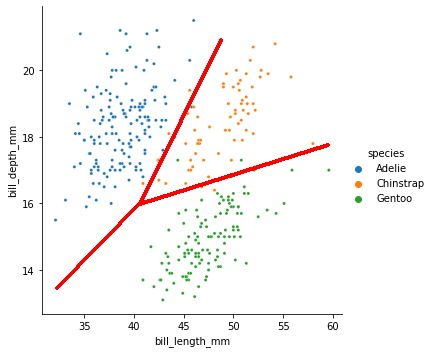
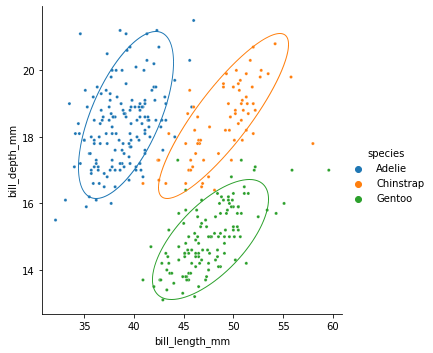

{kind=link}